published on May 09, 2022 in devlog
Martin sheds some light on the outage from over the weekend, and Michi shows off a new notification tool.

Martin
As many of you have probably noticed, we had a somewhat longer outage this weekend, which is something that tends to happen on a Saturday night when Michi is out with friends and I am travelling on a train :). I wanted to give a brief post-mortem about what happened, as it also relates to some of other performance issues we've seen since the Steam launch.
The first and most important piece of info is that since the launch, our active player numbers have effectively doubled (yay!). For a short while after the launch, they even trippled (using a very liberal definition of "active"). Initially, our cluster dealt with this surprisingly well, and we saw very few issues. But, as those active players grew in the game, so did the actual load. Especially in the European evening hours, when the US comes online, we've seen a regular increase in load.
(Warning, tech stuff ahead!) Now, the backend server of PrUn is written in Java. While there are a lot of good reasons to use Java, one of the biggest drawbacks of the language is the fact that it is "garbage-collected", meaning some CPU cycles are constantly required to purge obsolete objects from memory. The PrUn server nodes run in a cluster, sharing resources with other programs. As such, there are hard limits in place on how much memory and how many CPU cycles any program is allowed to use. In our monitoring, we were seeing that PrUn was creeping up towards the memory limit, so when we started seeing cluster nodes restarting for the first time, we assumed they were running out of memory. So we increased the limit, which brought some improvements, but didn't solve the issue. Reboots were less frequent, but they still happened.
On Saturday night, this ended up in a cascade: When one server node crashes, the remaining ones have to pick up the slack for a while until the replacement node comes up. All the rebalancing that happens during that process adds some extra load, too. Not to mention the huge amounts of "garbage objects" that need to be collected while entities are loaded from the database. So when the first node crashed, the others crashed, too. And when I tried bringing the cluster back up from zero, we saw node failures even during a clean restart (by nature a high-load situation). The cluster stumbled again the very moment it started accepting client connections, or even before it was available again.
I realized a bit too late that the nodes didn't actually die because they were out of memory, or because they were killed by the cluster manager for exceeding some resource limit, but they were shutting themselves down due to "loss of contact" to the other nodes. My first instinct was that the network load might just be too high, with nodes communicating among each other during reboot and hundreds of clients being connected. But it turns out I was looking in the wrong direction, and the problem was actually caused by garbage collection: As said, garbage collection requires processing cycles. And it requires a lot of them if there is a lot of garbage to collect. When the VM is busy collecting garbage, it has less cycles to spend on other tasks, which means other things just take longer. If a cluster node is waiting to hear back from another node, it can't differentiate between a response just taking a long time and a node being down (yay, distributed systems!). So after a while, when responses don't come back in time, the other node is deemed "unreachable" and kicked out of the cluster eventually.
(Far too) long story short: After simply increasing the CPU limit for our server nodes, everything stabilized immediately. The usual operational load is usually quite low, but there are occasional spikes in load, which are now covered by the higher limit. So far, things are looking good. But more investigation, hardening and monitoring are definitely on our agenda.
I hope you enjoyed this little disaster report...I hope I don't have to write too many of these in the future. I will see you again in July, as I will be on a 2-month parental leave starting next weekend. I'll be leaving the ship in the capable hands of the rest of the team!

Nick
Last week I worked on a lot of smaller tasks that had gotten a bit overlooked because of the Steam release. I started contacting and recontacting influencers for more YouTube content as well as working out how to get better Twitch content. Twitch has been a bit of conundrum for us since the game doesn't lend itself extremely well to streaming content. I've contacted a few Twitch streamers that seem to understand our problems with streaming and we've found some work-arounds like using two accounts to show both the start of the game and also more advanced play styles. Of course this will require the streamers to work a bit more on our product than other games, but I'm confident we can find a beneficial solution for everyone.
I also worked on updating the website with the Steam release and contacting Steam Curators that can leave a good word about the game for players that follow them on Steam. Our reviews are also looking a lot better now so everyone is happy about that! Thanks for everyone that has been helping with reviews, it really means so much to us :)

Michi (molp)
Besides assisting Martin with the outage on the weekend, I also spent a large amount of time last week on improving the internal tools. We use them to monitor the servers' performance and also pinpoint locations where things break. With the recent influx of Steam players, our system is pushed to limits that had not been reached before, and we will learn new things about it every week. Some of the issues caused can be anticipated beforehand, but others not so much.
Unfortunately, downtimes cannot be prevented entirely. If something breaks, it will immediately affect a lot of players, and there is not much that we can do, other than trying to react as fast as possible. For maintenance that is planned, I wrote a small server notification tool in order to communicate these downtimes better. It looks like this:
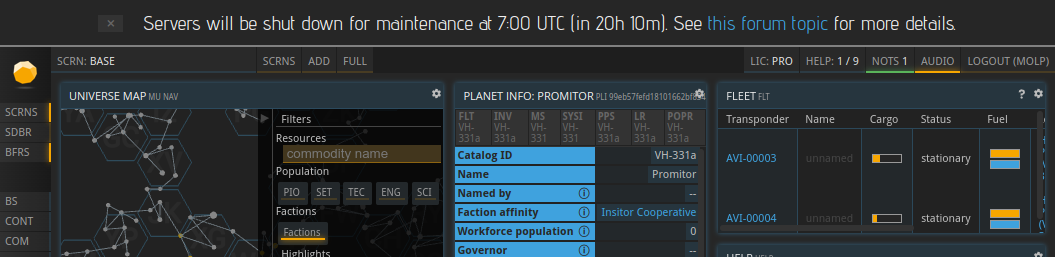
Using this server notification tool, we can notify all active players no matter if they use Discord, visit the forums, or scan the general chat. Each notification can be marked as seen with the little x button on the left and then will not be shown again. They also have an expiry date after which, they will disappear automatically.
As always: we'd love to hear what you think: join us on Discord or the forums!
Happy trading!